
This Help topic refers to the following editions:
þ Enterprise þProfessional þ Personal þ Small Business
From the DocuXplorer Desktop Ribbon Tab select Home | Options | Image Processing
The  symbol next to a property group indicates that settings are applied globally
to all users. If the symbol is absent, settings apply only to the currently
logged-in user.
symbol next to a property group indicates that settings are applied globally
to all users. If the symbol is absent, settings apply only to the currently
logged-in user.
All properties can be changed by the administrator or the currently logged-in user.
Image Processing settings bridge the gap between standardized product behavior and individual user requirements. These configurations manage key functional areas, including Quick Scan Settings, Scanning Preview Window, Optical Character Recognition, and Image Display Settings.
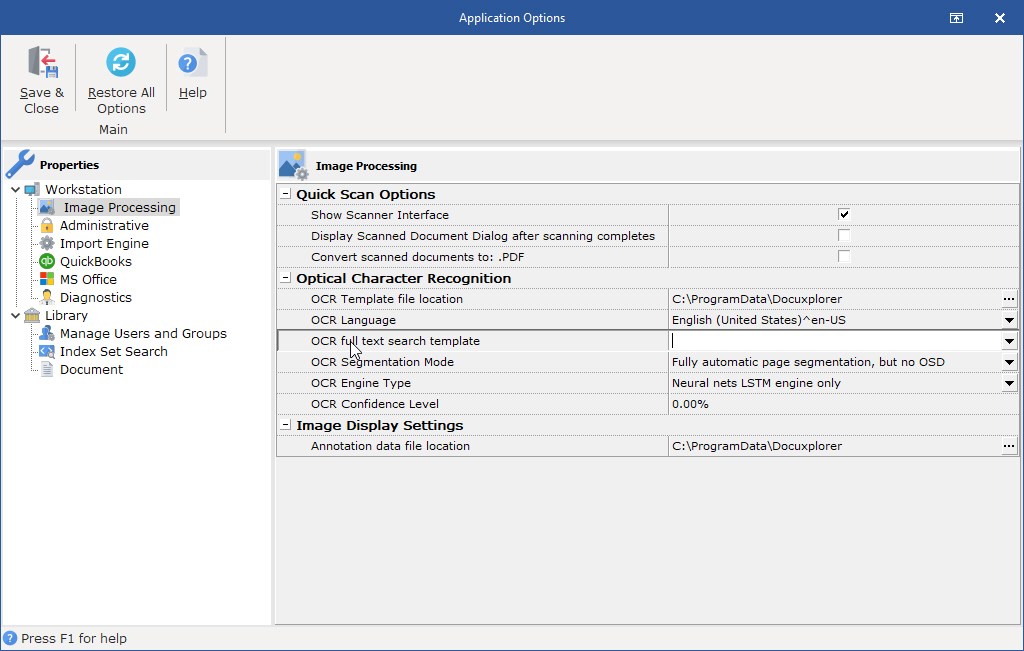
Quick Scan Options
Show Twain Interface - this option when checked will force DocuXplorer to display the scanner's Twain interface when scanning new pages.
Display Scanned Document Dialog after scanning completes - check box to display the Scanned Document dialog box only after scanning completes to view the scan quality and add additional pages.
Convert scanned documents to PDF - by selecting the check box all scanned documents using the Quick Scan option will automatically be converted to PDF format. DocuXplorer will not automatically convert scanned images to PDF when using the Scanner/Camera option. When using the Scanner/Camera options Save and Close the image, right-click and select <Convert Document to: PDF>.
Optical Character Recognition
OCR Zone data file location - This file holds
the information for OCR templates that are created for automated data
entry processing. If the file is placed on a network drive make sure users
have read and write access to it.
OCR Engine Type - The OCR engine can work at varying speeds Fast, Medium
and Slow. Fast is the default and produces results that are acceptable
for most document types. Medium and Slow, as the text implies work slower
but with higher degree of accuracy.
OCR Segmentation Mode - The OCR engine can work with varying layout of on a page. By default the OCR engine expects a page of text when it segments an image. If you're just seeking to OCR a small region try a different segmentation mode. Note that adding a white border to text which is too tightly cropped may also help
Orientation and script detection (OSD) only.
Automatic page segmentation with OSD.
Automatic page segmentation, but no OSD, or OCR.
Fully automatic page segmentation, but no OSD. (Default)
Assume a single column of text of variable sizes.
Assume a single uniform block of vertically aligned text.
Assume a single uniform block of text.
Treat the image as a single text line.
Treat the image as a single word.
Treat the image as a single word in a circle.
Treat the image as a single character.
Sparse text. Find as much text as possible in no particular order.
Sparse text with OSD.
Raw line. Treat the image as a single text line,
OCR Engine - Generally, LTSM should always be used, providing significant speed and accuracy benefits:
Legacy engine only: Uses the older engine (from IEVision 4.5.2 and older)
Neural nets LSTM engine only: Uses the new LTSM OCR engine (faster and more accurate than Legacy)
Legacy + LSTM engines: Uses either LTSM or Legacy
Default, based on what is available: Uses LTSM if newer TrainedData files are available, otherwise falls back to Legacy
https://github.com/tesseract-ocr/tesseract/wiki/4.0-Accuracy-and-Performance
OCR Language - This option allows a user to change the default language that is used to perform OCR text extraction on documents. If this option is left blank (the default), then the selected interface language is used for the OCR process.
Image Display Settings
Rubber Stamp data file location - This file holds the rubber stamps information defined when editing tiff documents. If the file is placed on a network drive make sure users have read and write access to it.